
In “A Cognitive Architecture for Machine Consciousness and Artificial Superintelligence: Thought Is Structured by the Iterative Updating of Working Memory” (arXiv:2203.17255), I, Jared Reser lay out a proposal for what a thought process would look like if we tried to engineer it directly into AI, rather than treating intelligence as something that falls out of ever-larger pattern recognizers.
You can also see this article at aithought.com with videos.
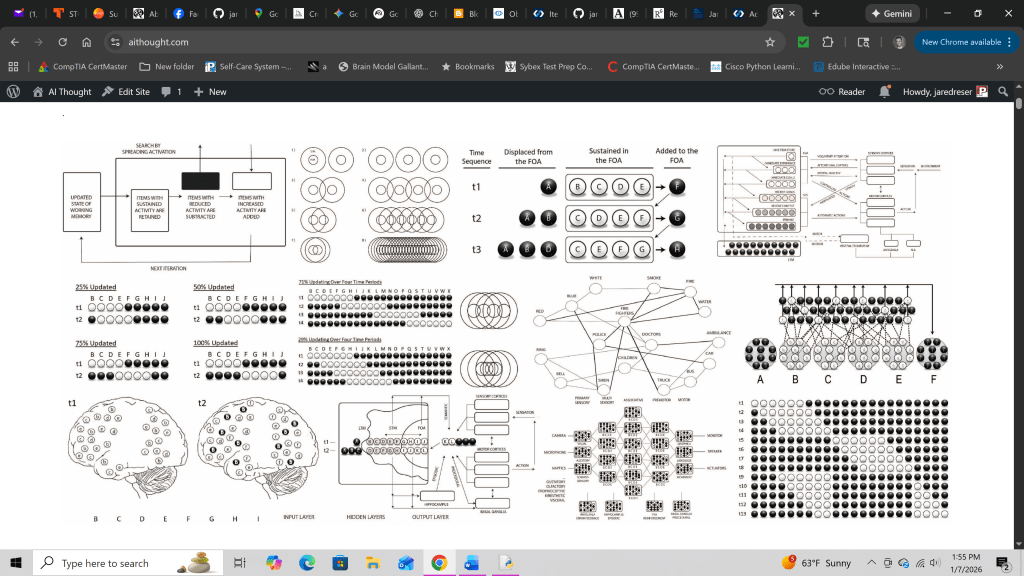
The paper’s central claim is simple to state: the workflow of thought is iterative. Instead of one working-memory state being replaced wholesale by the next, each new state should preserve some proportion of the previous state while adding and subtracting other elements. This “partial updating” causes successive states to overlap, so a train of thought becomes a chain of intermediate states that remain causally and semantically linked over time.
I argue that this overlap is not just a philosophical gloss, it’s grounded in the biology of persistent activity. Mammalian working memory is framed as having two key persistence mechanisms operating on different time scales: sustained firing (seconds) supporting the focus of attention, and synaptic potentiation (minutes to hours) supporting a broader short-term store. In this view, as some items drop out and others enter, the remaining coactive subset “stitches” the stream together, making continuity and multi-step reasoning possible.
Crucially, the paper doesn’t stop at saying states overlap. It proposes a mechanism for how the next update is chosen: the currently coactive working-memory contents jointly “cospread” activation across the network, performing a multiassociative search over long-term memory for the most context-relevant next addition(s). This repeated “search → update → search again (with modified context)” is presented as a compounding process that can build structured inferences, predictions, and plans across multiple steps.
Because the manuscript is meant to be both explanatory and constructive, it also explicitly positions iterative updating as an engineering blueprint: a way to implement a global-workspace-like working set that is updated continuously, supports long-range dependencies, and can be trained developmentally by expanding persistence/overlap over time. The paper even provides a glossary of introduced terms (e.g., iterative updating, cospreading, multiassociative search, SSC/icSSC, iterative compounding, iterative thread) intended to carve the system into reusable conceptual parts.
What this blog entry will do
In the rest of this post, I’ll first list a set of concrete claims and “working insights” extracted from the paper, phrased as testable or at least operationally meaningful statements. Then I’ll attempt to formalize several of the key ideas mathematically, with the goal of turning the architecture into something that can be simulated, ablated, and compared against alternatives (both in cognitive modeling and in AI implementations).
A) Core computational principle
- Thought is organized by continuous partial updating: each new working-memory state preserves a proportion of the prior state (not complete replacement), making the stream of thought a chain of overlapping iterations.
- Iterative overlap is the mechanism of continuity: overlap between successive working-memory states creates “recursive nesting” so each state is embedded in the one before it, enabling stateful cognition rather than stateless reactions.
- Iterative updating is simultaneously (i) an information-processing strategy, (ii) a model of working memory, (iii) a theory of consciousness, and (iv) an AI programming principle. Cognitive Architecture Iterativ…
B) Working memory structure: two persistence tiers + iteration in both
- Working memory has two key persistence mechanisms with different timescales: sustained firing maintains the FoA (seconds), while synaptic potentiation maintains a broader short-term store (minutes to hours).
- Both stores iterate: the FoA iterates via sustained firing; the short-term store iterates as a pool of synaptically potentiated units that is continuously added to and subtracted from, yielding isomorphic “incremental updating” across neural and psychological levels. Cognitive Architecture Iterativ…
- The persisting “topic” of thought corresponds to the longest-lasting active units, while other contextual features come and go around it. Cognitive Architecture Iterativ…
C) Control variables and “modes” of thought
- Rate of updating is a control parameter (how much of the set changes per step) that tunes looseness vs tightness of coupling—superficial/distractible vs concentrated/systematic processing.
- Implicit vs explicit processing is framed as different overlap regimes (system-1-like = faster updating / less overlap; system-2-like = slower updating / more overlap and longer maintenance of intermediates). Cognitive Architecture Iterativ…
- Dopamine is proposed to reduce the rate of updating (stabilize the set), mediating a shift toward explicit/effortful processing under novelty/surprise/reward/error. Cognitive Architecture Iterativ…
- Boundaries between “thoughts” are marked by intermittent non-iterative updates (high-percentage replacement events), while within-thought processing shows sustained low-percentage turnover. Cognitive Architecture Iterativ…
D) How new content is selected: pooled search (multiassociative search)
- Selection of the next update is a pooled spreading-activation search: the currently coactive set combines (“cospreads”) activation energy through the global network to converge on the most context-relevant next item(s).
- Multiassociative search is described as an explicit stepwise algorithm (items maintained vs dropped vs newly activated; plus mechanisms where the newest addition redistributes activation weights and can contextually alter the “fuzzy” composition/meaning of items). Cognitive Architecture Iterativ…
- The search contributors are not just FoA items: potentiated short-term-store units plus active sensory/motor cortex, hippocampus, basal ganglia, and other systems all contribute to the pooled search that selects the next update.
- Multiassociative search produces novel inference as a standard case: even when the set of assemblies is unprecedented, the system can converge on either recall (same result as last time) or a new item (novel inference) depending on current coactivity.
- Multiassociative search implies multiassociative learning: each search event can retune associative strengths (Hebbian-style), so search doesn’t just use memory—it updates semantic/procedural structure over time. Cognitive Architecture Iterativ…
E) Prediction and inference as the product of iteration
- Updates generated by search are predictions: iterative updating + pooled search is framed as a brain-level autoregressive mechanism that captures conditional dependencies across sequences of events.
- Iterative compounding: the product of one search becomes part of the next state’s cue-set, so search is repeatedly modified by its own outputs, compounding inferences/predictions across steps.
F) Reasoning patterns as working-memory dynamics (figures → mechanisms)
- Iterative inhibition: when the newest update is judged unhelpful/prepotent, it is inhibited so the remaining set must converge on the next-most-pertinent item; repeated inhibition rounds progressively restrict the search tree. Cognitive Architecture Iterativ…
- Planning = dense iteration: planning is characterized as (i) lower update rate, (ii) fewer full “jumps,” and (iii) more intermediate iterations before action—explicitly mapping planning to “chain-of-thought-like” intermediate steps.
- Attractor states as beliefs/truths: iterative updating tends to converge toward stable item-sets (attractors) interpreted as beliefs; thinking is framed as progressive narrowing/compression toward generalizable statements. Cognitive Architecture Iterativ…
G) Threading, subproblems, and compositional problem solving
- Iterative thread: a line of thought is a chain of iteratively updated states that can be reiterated or “picked up where it left off.”
- Subproblem decomposition via store cooperation: the FoA iterates on a subproblem while the short-term store holds the broader objective; interim results can be suspended and later reactivated.
- Merging of subsolutions: outputs from separate iterative episodes can be coactivated in a new state and used together for multiassociative search to yield a hybrid/final solution.
- Backward reference / conditional branching emerges when prior threads/subsolutions are stored and later reconverged upon, allowing departures from the default forward-iterative flow.
- Schemas as dynamic packets that can be recalled and co-iterated: a previously learned multi-item schema can be pulled in midstream and used as an organizing heuristic/script that iterates with the current line of thought.
- Transfer learning as “recognize partial overlap → import prior thread content”: encountering a later situation that shares items with an earlier episode triggers reuse of prior iterative structure to generalize toward a similar conclusion. Cognitive Architecture Iterativ…
H) AI training/development implications (as stated)
- Maturational training schedule for AI: start with minimal working-memory span/overlap and gradually expand toward superhuman span as experience accumulates. Cognitive Architecture Iterativ…
- Long-horizon inference depends on persistence preventing “cache misses”: prolonging persistence makes each search more specific (more constraints) and preserves intermediate results long enough to compound into higher-order inferences. Cognitive Architecture Iterativ…
Mathematical Formalization of Iterative Updating Working Memory
This section provides a minimal mathematical formalization of an iterative working-memory architecture in which (i) a limited-capacity focus-of-attention working set is updated incrementally over discrete cognitive iterations, (ii) the next working-memory content is selected by pooled multi-cue (multiassociative) search, and (iii) an inhibitory steering mechanism can suppress unhelpful candidates to force exploration of alternatives. The same formalization can be interpreted as a cognitive/neural process model or as an implementable AI module.
1. Representational Objects
Assume a universe of N candidate items (assemblies, concepts, perceptual features, memory entries, or latent vectors) indexed by i∈{1,…,N}. Each item has a representation vector in Rd.
Candidate pool
At iteration t, the system has access to a candidate poolCt∈RN×d,
where row Ct,i is the d-dimensional vector for candidate i. In an AI setting, Ct may be (a) token embeddings in a context window, (b) retrieved long-term memory vectors, (c) perceptual feature vectors, or (d) a mixture of all three.
Working memory (focus of attention)
Working memory is a capacity-limited set of K vectors:Wt∈RK×d.
We interpret Wt as the content currently held in the focus of attention (FoA). The core “iterative updating” assumption is that Wt+1 is formed by retaining a fraction of Wt and recruiting a fraction of new items from Ct, rather than replacing the entire content at each step.
Inhibition trace (optional)
To steer away from lures and repeated mistakes, maintain an inhibition state over candidates:ht∈R≥0N.
Large ht,i reduces the probability that candidate i is recruited at iteration t.
2. A Continuity Metric (Overlap)
A central measurable quantity is the degree to which successive working-memory states overlap. Because the AI implementation uses explicit “keep” masks, overlap is directly trackable.
Let Kt⊆{1,…,K} denote the set of indices of retained slots from Wt. Then a natural overlap statistic isOt=K∣Kt∣≈r,
where r∈[0,1] is the retention fraction (defined below). If the model uses “soft” retention (continuous gates), an analogous graded overlap can be computed from cosine similarity between pooled summaries of Wt and Wt+1.
Overlap is a control knob: increasing r produces more continuity and longer-horizon constraint accumulation; decreasing r produces faster topic shifts and more exploratory dynamics.
3. Pooled Multiassociative Search (Selecting New Content)
The next working-memory recruits are selected by a pooled search driven by the entire current working set. This can be implemented in a differentiable way using a pooled query vector.
Pooled query
Define a pooled queryqt=fpool(Wt)∈Rd,
where fpool is a learned pooling function. Common choices include mean-pooling plus an MLP,qt=MLP(K1k=1∑KWt,k),
or attention-based pooling,qt=k=1∑Kαt,kWt,k,αt=softmax(u⊤Wt),
with learnable vector u∈Rd.
Candidate logits (pooled similarity + inhibition)
Score each candidate by similarity to the pooled query, subtracting inhibition:ℓt,i=dqt⊤Ct,i+bi−λht,i,
where bi is an optional learned bias and λ≥0 controls the strength of inhibition.
Convert logits to a probability distribution:pt=softmax(ℓt/τ),
with temperature τ>0. Low τ yields near-deterministic convergence; higher τ yields more exploratory recruitment.
Recruiting m=(1−r)K new items
Let the number of new recruits bem=(1−r)K,
with retention fraction r∈[0,1]. Recruit m candidates from pt using a top-m operator (or a differentiable approximation).
Conceptually:
- Discrete: At=TopM(pt,m) (indices of the m strongest candidates)
- Differentiable: use Gumbel-Top-m (straight-through), soft top-k, or matching relaxations.
Let Rtnew∈Rm×d be the matrix of recruited vectors.
4. Retention / Eviction (Keeping rK Slots)
In addition to recruiting new items, the system decides which existing FoA slots to keep.
Keep scores
Assign a keep-score to each slot Wt,k given the current pooled context:gt,k=fkeep(Wt,k,qt)∈R,
where fkeep can be an MLP on concatenated inputs:gt,k=MLP([Wt,k;qt]).
Select rK slots to retain:
- Discrete: Kt=Top(gt,rK)
- Differentiable: relaxed top-k or straight-through top-k
Let Rtkeep∈RrK×d be the retained slot vectors.
5. The Iterative Updating Operator
The next working-memory state is formed by concatenating retained slots and new recruits:Wt+1=Concat(Rtkeep,Rtnew)∈RK×d.
This is the explicit retain–drop–add operator that makes overlap a controllable parameter. It also defines a concrete internal notion of “within-thought” continuity (high r) versus “thought boundary/reset” (low r or a reset event).
6. Iterative Inhibition (Search Steering)
To implement “reject-and-research” dynamics, we update the inhibition trace for candidates that were selected (or attempted) but deemed unhelpful.
Let zt∈[0,1]N be a (possibly soft) indicator of which candidates were selected at iteration t. Update inhibition asht+1=κht+γzt,
where κ∈[0,1) controls decay and γ>0 is the increment for selected/rejected candidates.
This mechanism progressively suppresses repeated lures and forces the pooled search to converge on alternatives, effectively pruning a local attractor basin.
7. Optional: Contextual “Meaning Shift” Within Working Memory
To capture context-dependent remapping (the idea that the “same item” can shift meaning depending on the most recent update and current set), define a context-conditioned transform applied to each slot before pooling:W^t,k=Wt,k+Δ(Wt,k,qt),
where Δ is a learned function (e.g., MLP). The pooled query is computed from W^t rather than Wt. This makes representational drift an explicit, measurable part of the model.
8. Training Objectives
The iterative working-memory module can be trained end-to-end inside larger models (transformer, recurrent agent, world model). The following losses are common and complementary.
8.1 Task loss (supervised or self-supervised)
If the system produces outputs yt (next token, next action, next-step label), train with a standard task loss:Ltask=t∑CE(yt,yt∗)orLtask=t∑∥yt−yt∗∥2.
8.2 Continuity regularization (optional)
To encourage a desired overlap regime, regularize the effective overlap O^t toward target r:Loverlap=t∑(O^t−r)2.
Here O^t can be computed from keep masks (discrete) or from similarity of pooled summaries (soft).
8.3 World-model prediction (optional)
For predictive learning, minimize error in predicting next observation features ϕ(ot+1):Lpred=t∑ϕ^t+1−ϕ(ot+1)2.
This loss incentivizes the module to retain what is causally relevant across time while updating what changes.
8.4 Reinforcement learning (optional)
In RL settings, Wt conditions the policy π(at∣Wt). The working-memory module is trained jointly by actor–critic losses; overlap/continuity regularizers can be added to shape deliberation.
9. Developmental / Curriculum Scheduling of Retention
A key architectural hypothesis is that long-horizon coherence can be scaffolded by gradually increasing retention and persistence. Implement this via a schedule for r over training steps:r(step)=rmin+(rmax−rmin)⋅σ(s1step−s0),
where σ(⋅) is the logistic function and s0,s1 control onset and steepness.
Early training (lower r) promotes exploration and rapid updating; later training (higher r) promotes compounding of intermediate results and stable long-horizon inference.
10. Key Knobs, Metrics, and Ablations
10.1 Knobs (interpretable control parameters)
- Capacity: K (FoA size)
- Retention / overlap: r (continuity)
- Selection temperature: τ (exploration vs convergence)
- Inhibition: λ,κ,γ (escape from lures)
- Pooling/keep functions: fpool,fkeep (learned control policy)
10.2 Metrics
- Overlap / continuity: Ot or O^t
- Reset frequency: incidence of low-overlap transitions
- Lure perseverance: probability of re-selecting recently inhibited candidates
- Long-horizon coherence: task-dependent (e.g., plan success, multi-step accuracy, discourse coherence)
10.3 Mechanism-proving ablations
Ablations that directly test whether each primitive matters:
- No overlap constraint: replace all K slots each step (set r=0)
- Overlap without pooled search: recruit using only the newest slot (single-cue)
- Pooled search without inhibition: remove ht terms (λ=0)
- Fixed rrr vs curriculum r(⋅)r(\cdot)r(⋅): test developmental hypothesis
- Remove contextual remapping: set Δ(⋅)=0
These ablations tend to produce characteristic failures (derailment, lure trapping, weak bridging inference) that operationalize the theory’s claims.
11. Summary (the “kernel”)
The architecture reduces to a small set of commitments:
- A capacity-limited working set Wt evolves by an explicit operator
Wt+1=KeeprK(Wt)∪Recruit(1−r)K(Ct∣fpool(Wt)),
- New recruits are selected by pooled multi-cue search (softmax over candidate similarity to a pooled query),
- Search can be steered by iterative inhibition,
- Retention r is an interpretable continuity knob that can be trained and scheduled.
This formalization is simultaneously (i) a theory statement (what cognition is doing step-to-step) and (ii) a runnable AI design pattern (how to build an agent that maintains continuity and compounds intermediate results).

Leave a comment